An OBJECT column gives the name of the object observed (usually a star name). Many instruments record only a code for the object, instead of a name. These codes must be turned into standard names for the observational-data tables. Presumably the owners of such instruments already have software to do this that can be cannibalized for the format conversion.
For measurements of dark current, the OBJECT column should contain the word DARK. As dark measurements must be referred to the electrical zero of the system, they are usually accompanied by such measurements. The electrical-zero values should be identified as ZERO in the OBJECT column. If no such data exist, they will be assumed numerically zero.
Naming the object is simple when the measurement is just star + sky; one normally uses the name of the star. However, sky observations must be matched up with the proper stars. This is not a trivial task, for multiple sky observations may be used for one single star, and multiple star observations may have to share a single sky measurement.
Thus, ``sky'' alone is not a sufficient identification; it must be something like ``sky for such-and-such a star''. A related problem is to know the coordinates where the sky is observed, which are needed in modelling the sky brightness. In critical cases, it is common practice to measure sky on two or more positions around a target object, and these positions must be identified. Finally, we must be able to use sky-subtracted data, for which the sky brightness may no longer be available (some CCD photometry falls in this category).
A general treatment of this problem requires a column called OBJECT, bearing the usual name of the object (as in the star tables); a column labelled STARSKY, to distinguish between star+sky, star alone, or sky alone; and additional columns to identify the sky position.
Valid strings for the STARSKY column are STAR for the sum (star + sky); SKY for sky alone; and DIFF for the difference. The latter is often produced in CCD photometry. Note that SKY data may still be useful in this case.
The position where sky was measured can be specified by its
offsets from the star in both coordinates.
Usually, these will be in two columns
named SKYOFFSETRA and SKYOFFSETDEC, to identify the sky position used.
These are convenient in most cases, as observers usually offset in just one
coordinate.
Often only one sky position is used, nearly always offset in the same direction.
For users of alt-azimuth mountings, these labels can be replaced by
SKYOFFSETALT and SKYOFFSETAZ;
see Table ![]() .
.
It can be foreseen that lazy observers will fill up these columns with zeroes. They should be warned that assuming the sky position to coincide with the star, combined with measuring the sky always on the same side of a star, can introduce systematic errors, because of the gradient of sky brightness with zenith distance. For faint stars this may not be negligible, particularly if the offset is always in declination, which tends to correlate strongly with zenith distance.
Some telescopes record the apparent position of each measurement.
In such cases, it will be more convenient to use columns named
SKYRA and SKYDEC instead of offsets
(see Table ![]() ).
).
In clusters and variable-star fields, the sky may be measured in a common position for a group of stars. In this case, the observations of a group are delimited by putting BEGINGROUP in the OBJECT column at the start of the group, and ENDGROUP at the end. Then the sky position(s) should be given as absolute coordinates in a star-catalog MIDAS table file, identified there as a string beginning with the word SKY. The R.A. and Dec. for these sky positions can generally be determined accurately enough by reference to some star on finding charts, or by interpolation among the known positions of variable and comparison stars. Normally, these reference sky positions will simply be included in the program-star table files, with OBJECT names like 'SKY for NGC 7789' or 'SKY position 1 for RU Lupi'. This allows several distinct sky positions to be measured in the neighborhood of such a group.
Because MIDAS tables may in principle be sorted on any column, and because groups delimited by BEGINGROUP and ENDGROUP are inherently time-dependent, programs using such data must make sure the data are sorted in time sequence. This is not normally a problem, as time is the natural independent variable in such a list of observations. However, observers must be sure that the MJD_OBS column is correct for the BEGINGROUP and ENDGROUP pseudo-objects.
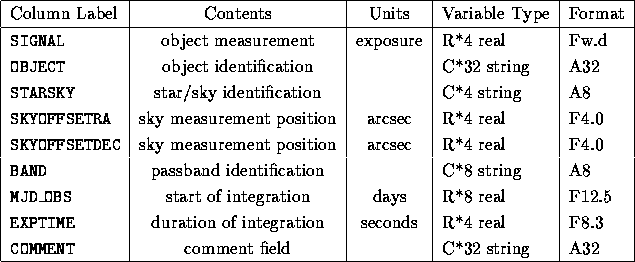
Table: Basic column specifications for observational-data tables