

This chapter is comprised of a brief description of the basics of spectral fitting, their application in XSPEC, and some helpful hints on how to approach particular problems. We then provide more details about the way XSPEC12 is constructed to add flexibility in its approach to the minimization problem. We also describe the data formats accepted by the initial release.
The Basics of Spectral Fitting
Although we use a spectrometer to try to find out the spectrum of a source, what the spectrometer obtains is not the actual spectrum, but rather photon counts (C) within specific instrument channels, (I). This observed spectrum is related to the actual spectrum of the source (f(E)), such that:
![]()
Where R(I,E) is the instrumental response and is proportional to the probability that an incoming photon of energy E will be detected in channel I. Ideally, then, we would like to determine the actual spectrum of a source, f(E), by inverting this equation, thus deriving f(E) for a given set of C(I). Regrettably, this is not possible in general, as such inversions tend to be non-unique and unstable to small changes in C(I). (For examples of attempts to circumvent these problems see Blissett & Cruise 1979; Kahn & Blissett 1980; Loredo & Epstein 1989).
The usual alternative is to try to choose a model spectrum, f(E), that can be described in terms of a few parameters (i.e., f(E,p1,p2,...)), and match, or “fit” it to the data obtained by the spectrometer. For each f(E), a predicted count spectrum (Cp(I)) is calculated and compared to the observed data (C(I)). Then a “fit statistic'” is computed from the comparison, which enables one to judge whether the model spectrum “fits” the data obtained by the spectrometer.
The model parameters then are varied to find the parameter values that give the most desirable fit statistic. These values are referred to as the best-fit parameters. The model spectrum, fb(E), made up of the best-fit parameters is considered to be the best-fit model.
The most common fit statistic in use for determining the
“best-fit” model is![]() ,
defined as follows:
,
defined as follows:
![]()
where σ(I) is the error
for channel I (e.g., if C(I) are counts then σ(I) is usually
estimated by ![]() ; see
e.g. Wheaton et.al. 1995 for other possibilities).
; see
e.g. Wheaton et.al. 1995 for other possibilities).
Once a “best-fit” model is obtained, one must ask two questions:
1. First,
one must ask how confident one can be that the observed C(I) can have
been produced by the best-fit model fb(E). The answer to
this question is known as the “goodness-of-fit” of the model. The ![]() statistic
provides a well-known-goodness-of-fit criterion for a given number of degrees
of freedom (ν, which is calculated as the number of channels minus the
number of model parameters) and for a given confidence level. If
statistic
provides a well-known-goodness-of-fit criterion for a given number of degrees
of freedom (ν, which is calculated as the number of channels minus the
number of model parameters) and for a given confidence level. If ![]() exceeds a
critical value (tabulated in many statistics texts) one can conclude that fb(E)
is not an adequate model for C(I). As a general rule, one wants
the “reduced
exceeds a
critical value (tabulated in many statistics texts) one can conclude that fb(E)
is not an adequate model for C(I). As a general rule, one wants
the “reduced ![]() ”
” ![]() to be
approximately equal to one
to be
approximately equal to one ![]() . A reduced
. A reduced ![]() that is much greater than one indicates a poor fit,
while a reduced
that is much greater than one indicates a poor fit,
while a reduced ![]() that
is much less than one indicates that the errors on the data have been
over-estimated. Even if the best-fit model (fb(E)) does
pass the “goodness-of-fit” test, one still cannot say that fb(E)
is the only acceptable model. For example, if the data used in the fit
are not particularly good, one may be able to find many different models for
which adequate fits can be found. In such a case, the choice of the correct
model to fit is a matter of scientific judgment.
that
is much less than one indicates that the errors on the data have been
over-estimated. Even if the best-fit model (fb(E)) does
pass the “goodness-of-fit” test, one still cannot say that fb(E)
is the only acceptable model. For example, if the data used in the fit
are not particularly good, one may be able to find many different models for
which adequate fits can be found. In such a case, the choice of the correct
model to fit is a matter of scientific judgment.
2. Second, for a given best-fit parameter (p1), one must determine the range of values within which one can be confident the true value of the parameter lies. The answer to this question gives one the “confidence interval” for the parameter.
The
confidence interval for a given parameter is computed by varying the parameter
value until the ![]() increases
by a particular amount above the minimum, or “best-fit” value. The amount that
the
increases
by a particular amount above the minimum, or “best-fit” value. The amount that
the ![]() is allowed
to increase (also referred to as the critical
is allowed
to increase (also referred to as the critical ![]() ) depends on the confidence level one requires,
and on the number of parameters whose confidence space is being calculated.
The critical
) depends on the confidence level one requires,
and on the number of parameters whose confidence space is being calculated.
The critical ![]() for
common cases are given in the following table (from Avni, 1976):
for
common cases are given in the following table (from Avni, 1976):
|
Confidence |
Parameters |
||
|
|
1 |
2 |
3 |
|
0.68 |
1.00 |
2.30 |
3.50 |
|
0.90 |
2.71 |
4.61 |
6.25 |
|
0.99 |
6.63 |
9.21 |
11.30 |
To summarize the preceding section, the main components of spectral fitting are as follows:
·
A set of one or more observed spectra ![]() with background measurements B(I) where available
with background measurements B(I) where available
·
The corresponding instrumental responses ![]()
·
A set of model spectra ![]()
· These components are used in the following manner:
· A parameterized model is created that one feels represents the actual spectrum of the source.
· One then gives values to the model parameters.
· Based on the parameter values given, one predicts the count spectrum that would be detected by the spectrometer in a given channel for such a model.
· Then, one compares the predicted spectrum to the spectrum actually obtained by the instrument.
· The values of the parameters of the model are manipulated until one finds the best fit between the theoretical model and the observed data.
One then calculates the “goodness” of the fit to determine how well the model explains the observed data, and calculates the confidence intervals for the model's parameters.
This section describes how XSPEC performs these tasks.
To obtain each observed spectrum, ![]() , XSPEC uses two files:
the data (spectrum) file, containing D(I), and the background file,
containing B(I). The data file tells XSPEC how many total photon counts
were detected by the instrument in a given channel. XSPEC then uses the
background file to derive the set of background-subtracted spectra C(I)
in units of counts per second. The background-subtracted count rate is given
by, for each spectrum:
, XSPEC uses two files:
the data (spectrum) file, containing D(I), and the background file,
containing B(I). The data file tells XSPEC how many total photon counts
were detected by the instrument in a given channel. XSPEC then uses the
background file to derive the set of background-subtracted spectra C(I)
in units of counts per second. The background-subtracted count rate is given
by, for each spectrum:
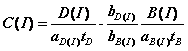
where ![]() and
and
![]() are the counts
in the data and background files;
are the counts
in the data and background files; ![]() and
and
![]() are the
exposure times in the data and background files;
are the
exposure times in the data and background files; ![]() and
and ![]() ,
,
![]() and
and ![]() are the
background and area scaling values from the spectrum and background
respectively, which together refer the background flux to the same area as the
observation as necessary. When this is done, XSPEC has an observed spectrum to
which the model spectrum can be fit.
are the
background and area scaling values from the spectrum and background
respectively, which together refer the background flux to the same area as the
observation as necessary. When this is done, XSPEC has an observed spectrum to
which the model spectrum can be fit.
R(I,E): The Instrumental Response
Before XSPEC can take a given set of parameter values and
predict the spectrum that would be detected by a given instrument, XSPEC must
know the specific characteristics of the instrument. This information is known
as the detector response. Recall that for each spectrum the response ![]() is
proportional to the probability that an incoming photon of energy E will be
detected in channel I. As such, the response is a continuous function of E.
This continuous function is converted to a discrete function by the creator of
a response matrix who defines the energy ranges
is
proportional to the probability that an incoming photon of energy E will be
detected in channel I. As such, the response is a continuous function of E.
This continuous function is converted to a discrete function by the creator of
a response matrix who defines the energy ranges ![]() such that:
such that:
 dE)/(E(J) - E(J-1))](XspecSpectralFitting_files/image023.gif)
XSPEC reads both the energy ranges, ![]() , and the
response matrix
, and the
response matrix ![]() from
a response file in a compressed format that only stores non-zero elements.
XSPEC also includes an option to use an auxiliary response file, which contains
an array
from
a response file in a compressed format that only stores non-zero elements.
XSPEC also includes an option to use an auxiliary response file, which contains
an array ![]() that XSPEC
multiplies into
that XSPEC
multiplies into ![]() as
follows:
as
follows:
![]()
This array is designed to represent the efficiency of the detector with the response file representing a normalized Redistribution Matrix Function, or RMF. Conventionally, the response is in units of cm2.
The model spectrum, ![]() , is calculated within XSPEC using the energy ranges defined
by the response file :
, is calculated within XSPEC using the energy ranges defined
by the response file :
 dE)](XspecSpectralFitting_files/image028.gif)
and is in units of photons cm-2s-1. XSPEC allows the construction of composite models consisting of additive components representing X-ray sources (e.g., power-laws, blackbodys, and so forth), multiplicative components, which modify additive components by an energy-dependent factor (e.g., photoelectric absorption, edges, ...). Convolution and mixing models can then perform sophisticated operations on the result. Models are defined in algebraic notation.
For example, the following expression:
phabs (power + phabs (bbody))
defines an absorbed blackbody, phabs(bbody), added to a power-law, power. The result then is modified by another absorption component, phabs. For a more detailed explanation of models, see Chapter 6.
Once data have been read in and a model defined, XSPEC uses a fitting algorithm to find the best-fit values of the model parameter. The default is a modified Levenberg-Marquardt algorithm (based on CURFIT from Bevington, 1969). The algorithm used is local rather than global, so the user should be aware that it is possible for the fitting process to get stuck in a local minimum and not find the global best-fit. The process also goes much faster (and is more likely to find the true minimum) if the initial model parameters are set to sensible values.
At the end of a fit, XSPEC will write out the best-fit parameter values, along with estimated confidence intervals. These confidence intervals are one sigma and are calculated from the derivatives of the fit statistic with respect to the model parameters. However, the confidence intervals are not reliable and should be used for indicative purposes only.
XSPEC has a separate command (error or uncertain) to derive confidence intervals for one interesting parameter, which it does by fixing the parameter of interest at a particular value and fitting for all the other parameters. New values of the parameter of interest are chosen until the appropriate delta-statistic value is obtained. XSPEC uses a bracketing algorithm followed by an iterative cubic interpolation to find the parameter value at each end of the confidence interval.
To compute confidence regions for several parameters at a time, XSPEC can run a grid on these parameters. XSPEC also will display a contour plot of the confidence regions of any two parameters.
In the new version, programmed using abstraction techniques, XSPEC considers the following problem:
Given a set of spectra C(I), each supplied as a function of detector channels, a set of theoretical models {M(E)j} each expressed in terms of a vector of energies together with a set of functions {R(I,E)j} that map channels to energies, minimize an objective function S of C, {R(I,E)i}, {M(E)j} using a fitting algorithm, i.e.
![]()
In the default case, this reduces to the specific expression
for ![]() fitting of
a single source
fitting of
a single source
![]()
where ![]() runs
over all of the channels in all of the spectra being fitted, and using the
Levenberg-Marquadt algorithm to perform the fitting.
runs
over all of the channels in all of the spectra being fitted, and using the
Levenberg-Marquadt algorithm to perform the fitting.
This differs from the previous formulation in that XSPEC12’s operations that control the fitting process make fewer assumptions about how the data are formatted, what function is being minimized, and which algorithm is being employed. XSPEC12 thus represents the fitting problem at a higher level of abstraction than previous versions. At the calculation level, XSPEC12 requires spectra, backgrounds, responses and models, but places much fewer constraints as to how they are represented on disk and how they are combined to compute the objective function (statistic). This has immediate implications for the extension of XSPEC analysis to future missions.
New data formats can be implemented independently of the existing code, so that they may be loaded during program execution. The ‘data format’ includes the specification not only of the files on disk but how they combine with models.
Multiple sources may be extracted from a spectrum. For
example, it generalizes the fitting problem to minimizing, in the case of the ![]() statistic,
statistic,
)^2)](XspecSpectralFitting_files/image032.gif)
and j runs over one or more models. This allows the analysis of coded aperture data where multiple sources may be spatially resolved.
Responses, which abstractly represent a mapping from the theoretical energy space of the model to the detector channel space, may be represented in new ways. For example, the INTEGRAL/SPI responses are implemented as a linear superposition of 3 (fixed) components.
Instead of combining responses and models through convolution XSPEC12 again places no prior constraint on how this combination is implemented. For example, analysis of data collected by future large detectors might take advantage of the form of the instrumental response by decomposing the response into components of different frequency.
Other differences of approach are in the selection of the statistic of the techniques used for deriving the solution. Statistics and fitting methods may now be added to XSPEC12 at execution time rather than at installation time, so that the analysis package as a whole may more easily kept apace of new techniques.
XSPEC Data Analysis
XSPEC12 is designed to support multiple input data formats. Support for the earlier SF format is removed, while support for the Einstein FITS format, a precusor to the OGIP format, is in progress. Also planned is support for ASCII data, which will allow XSPEC to analyze spectra from other wavelength regions (optical, radio) transparently to the user.
In the initial release of XSPEC12, the OGIP data format both for single spectrum files (Type I) and multiple spectrum files (Type II) is fully supported. These files can be created and manipulated with programs described in Appendix E and the provided links. The programs are described more fully in George et al. 1992. (the directories below refer to the FTOOLS distribution).
l Spectral Data: callib/src/gen/rdpha2.f, wtpha2.f
l Responses: callib/src/gen rdebd3.f, rdrmf4.f, wtebd3.f, wtrmf4.f. The “rmf” programs read and write the RMF extension, while the “ebd” programs write an extension called EBOUNDS that contains nominal energies for the detector channels.
l Auxiliary Responses: callib/src/gen rdarf1.f, and wtarf1.f
Also in the initial release an XSPEC12 module for reading and simulating INTEGRAL/SPI data is provided as an add-in module, loaded by the user on demand. The INTEGRAL/SPI datasets are similar to OGIP Type II, but contain an additional FITS extension that stores information on the multiple files used to construct the responses.
The initial release of XSPEC12 supports INTEGRAL/SPI data. The INTEGRAL Spectrometer (SPI) is a coded-mask telescope, with a 19-element Germanium detector array. The Spectral resolution is ~500, and the angular resolution is ~3°. Unlike focusing instruments however, the detected photons are not directionally tagged, and a statistical analysis procedure, using for example cross-correlation techniques, must be employed to reconstruct an image. The description of the XSPEC analysis approach[1] which follows assumes that an image reconstruction has already been performed; see the SPIROS utility within the INTEGRAL offline software analysis package (OSA), OR, the positions on the sky of all sources to be analyzed are already known (which is often the case). Those unfamiliar with INTEGRAL data analysis should refer to the OSA documentation. Thus, the INTEGRAL/SPI analysis chain must be run up to the event binning level [if the field of view (FoV) source content is known, e.g. from published catalogs, or from IBIS image analysis], or the image reconstruction level. SPIHIST should be run selecting the "PHA" output option, and selecting detectors 0-18. This will produce an OGIP standard type-II PHA spectral file, which contains multiple, detector count spectra. In addition, the SPIARF procedure should be run once for each source to be analyzed, plus one additional time to produce a special response for analysis of the instrumental background. If this is done correctly, and in the proper sequence, SPIARF will create a table in the PHA-II spectral file, which will associate each spectrum with the appropriate set of response matrices. The response matrices are then automatically loaded into XSPEC upon execution of the data command in a manner very transparent to the user. You will also need to run SPIRMF (unless you have opted to use the default energy bins of the template SPI RMFs). Finally, you will need to run the FTOOL SPIBKG_INIT. Each of these utilities - SPIHIST, SPIARF, SPIRMF and SPIBKG_INIT - are documented elsewhere, either in the INTEGRAL or (for SPIBKG_INIT the LHEASOFT/FTOOLS) software documentation.
There are several complications regarding the spectral
de-convolution of coded-aperture data. One already mentioned is the source
confusion issue; there may be multiple sources in the FoV, which are lead to
different degrees of shadowing on different detectors. Thus, a separate
instrumental response must be applied to a spectral model for each possible
source, for each detector. This is further compounded by the fact that
INTEGRAL's typical mode of observation is “dithering.” A single observation may
consist of ~10's of individual exposures at raster points separated by ~2°. This further enumerates the number of
individual response matrices required for the analysis. If there are multiple
sources in the FoV, then additional spectral models can be applied to an
additional set of response matrices, enumerated as before over detector and
dither pointing. This capability - to model more than one source at a time in a
given Chi-Square (or alternative) minimization procedure - did not exist in
previous versions of XSPEC. For an observation with the INTEGRAL/SPI
instrument, where the apparent detector efficiency is sensitive to the position
of the source on the sky relative to the axis of the instrument, the ![]() statistic is:
statistic is:
![chi-square = [sum over p][sum over d][sum over l]([D_dp(I)-[sum over j][sum over E](R_jdp(I,E)*M_j(E;x_s)-B_dp(I;x_s))]/sigma(I)_dp)^2)](XspecSpectralFitting_files/image034.gif)
where:
![]() run over
instrument pointings and detectors;
run over
instrument pointings and detectors;
I runs over individual detector channels
j enumerates
the sources detected in the field at different position ![]()
E indexes the energies in the source model
xs parameters of the source model, which is combined with the response
xb parameters of the background model, expressed as a function of detector channel
Examination of this equation reveals one more complication; the term B represents the background, which, unlike for chopping, scanning or imaging experiments, must be solved for simultaneously with the desired source content. The proportion of background-to-source counts for a bright source such as the Crab is ~1%. Furthermore, the background varies as a function of detector, and time (dither-points), making simple subtraction implausible. Thus, a model of the background is applied to a special response matrix, and included in the de-convolution algorithm.
Arnaud, K.A., George, I.M., Tennant, A.F., 1992. Legacy, 2, 65.
Avni, Y., 1976. ApJ, 210, 642.
Bevington, P.R., 2002, 3rd Edition. Data Reduction and Error Analysis for the
Physical Sciences, McGraw-Hill.
Blissett, R.J., Cruise, A.M., 1979. MNRAS, 186, 45.
George, I.M., Arnaud, K.A., Pence, W., Ruamsuwan, L., 1992. Legacy, 2, 51.
Kahn, S.M., Blissett, R.J., 1980. ApJ, 238, 417.
Loredo, T.J., Epstein, R.I., 1989. ApJ, 336, 896.
Press, W.H., Teukolsky, S.A., Vetterling, W.T., Flannery, B.P., 1992.
Numerical Recipes (2nd edition), p687ff, CUP.
Wheaton, W.A. et.al., 1995. ApJ, 438, 322.
[1] This is one of several possible analysis paths. The most commonly used method involves the SPIROS utility in spectral extraction mode, which leads to a effective-area corrected, background subtracted "pseudo-count" spectra. A (single) customized XSPEC RMF is then applied to approximate the photon-to-count redistribution for model fitting.